
「ローカルで動くAIと音声で会話できたら面白いのに」と思ったことはないだろうか。ChatGPTのような外部サービスに頼らなくても、Ollama(ローカルLLM)とVOICEVOX(音声合成エンジン)を組み合わせれば、完全にオフラインで動く音声会話AIアシスタントが作れる。
この記事では、Pythonスクリプト1本で「マイクに話しかける→AIが考える→VOICEVOXが読み上げる」という一連の流れを実現する方法を解説する。プライバシーを気にせず、好きなキャラの声でAIと会話できるのが最大の魅力だ。
Ollamaのインストールがまだの方は、ローカルPCにLLMをインストールして生成AIを使う方法(Ollama)を先に読んでほしい。モデル選びに迷ったらOllamaで使えるLLMモデル比較も参考になる。
仕組みの全体像
音声会話AIの処理フローはシンプルで、以下の3ステップをループさせるだけだ。
| ステップ | 役割 | 使うもの |
|---|---|---|
| 1. 音声認識(STT) | マイク入力をテキストに変換 | Google Speech Recognition / Whisper |
| 2. テキスト生成(LLM) | ユーザーの発言に対する応答を生成 | Ollama(Gemma 2, Qwen2.5 等) |
| 3. 音声合成(TTS) | 応答テキストを音声で読み上げ | VOICEVOX |
すべてローカルで完結するため、インターネット接続は不要(音声認識にGoogle APIを使う場合を除く)。会話内容が外部に送信されることもない。
必要な環境
| 項目 | 要件 |
|---|---|
| OS | Windows 10/11, macOS, Linux |
| Python | 3.10以上 |
| メモリ | 16GB以上推奨(LLMのサイズ次第) |
| GPU | あると高速(なくても動く) |
| マイク | PC内蔵 or USB/Bluetooth |
VOICEVOXのインストール
VOICEVOX公式サイトからインストーラーをダウンロードして実行する。Windows / macOS / Linux に対応している。
インストール後、VOICEVOXを起動すると内部でHTTPサーバー(デフォルト http://localhost:50021)が立ち上がる。このAPIを通じてPythonから音声合成を呼び出す仕組みだ。
GUIは使わなくてもエンジンだけ起動しておけばOK。タスクトレイに常駐していれば準備完了である。
VOICEVOXのキャラクター(話者)を確認する
VOICEVOXには複数のキャラクター(話者)が用意されている。使える話者の一覧はAPIで取得できる。
curl http://localhost:50021/speakers | python -m json.tool主な話者とIDの例:
| 話者名 | スタイル | speaker_id |
|---|---|---|
| 四国めたん | ノーマル | 2 |
| ずんだもん | ノーマル | 3 |
| 春日部つむぎ | ノーマル | 8 |
| 雨晴はう | ノーマル | 10 |
| 冥鳴ひまり | ノーマル | 14 |
好きなキャラのIDを控えておこう。後でスクリプト内で指定する。
Ollamaの準備
Ollamaがまだ入っていなければ、こちらの記事を参照してインストールしてほしい。
モデルは日本語が得意なものを選ぶのがポイント。おすすめは以下の通り。
| モデル | サイズ | 日本語品質 | 速度 |
|---|---|---|---|
| gemma2:9b | 約5.4GB | 良好 | 普通 |
| qwen2.5:7b | 約4.7GB | 良好 | 普通 |
| qwen2.5:3b | 約1.9GB | そこそこ | 速い |
| phi3:mini | 約2.3GB | まずまず | 速い |
会話のテンポを重視するなら軽量モデル(3b前後)、回答の質を重視するなら7b〜9bクラスがいいだろう。
ollama pull qwen2.5:7bPythonライブラリのインストール
必要なライブラリをまとめてインストールする。
pip install SpeechRecognition pyaudio requests ollama各ライブラリの役割は以下の通り。
| ライブラリ | 役割 |
|---|---|
| SpeechRecognition | マイク入力の音声認識 |
| PyAudio | マイクの音声キャプチャ |
| requests | VOICEVOX APIとの通信 |
| ollama | Ollama APIとの通信 |
PyAudioのインストールでエラーが出る場合
WindowsでPyAudioのインストールに失敗する場合は、以下を試してみてほしい。
# Windows の場合
pip install pipwin
pipwin install pyaudio
# または直接whlファイルを指定
pip install PyAudio-0.2.14-cp311-cp311-win_amd64.whlLinuxの場合は portaudio の開発パッケージが必要になる。
# Ubuntu / Debian
sudo apt install portaudio19-dev python3-pyaudio
# Fedora / AlmaLinux
sudo dnf install portaudio-devel音声会話スクリプトの全体コード
以下が音声会話AIアシスタントの完成コードだ。ファイル名は voice_assistant.py として保存する。
import speech_recognition as sr
import requests
import json
import wave
import io
import ollama
# --- 設定 ---
VOICEVOX_HOST = "http://localhost:50021"
OLLAMA_MODEL = "qwen2.5:7b"
SPEAKER_ID = 3 # ずんだもん(ノーマル)
SYSTEM_PROMPT = "あなたは親切なAIアシスタントです。日本語で簡潔に答えてください。"
# 会話履歴を保持
conversation_history = [
{"role": "system", "content": SYSTEM_PROMPT}
]
def listen_from_mic():
"""マイクから音声を取得してテキストに変換する"""
recognizer = sr.Recognizer()
with sr.Microphone() as source:
print("\n[*] 聞いています... (話しかけてください)")
recognizer.adjust_for_ambient_noise(source, duration=0.5)
try:
audio = recognizer.listen(source, timeout=10, phrase_time_limit=30)
print("[*] 認識中...")
text = recognizer.recognize_google(audio, language="ja-JP")
print(f"[あなた] {text}")
return text
except sr.WaitTimeoutError:
print("[!] タイムアウト: 音声が検出されませんでした")
return None
except sr.UnknownValueError:
print("[!] 音声を認識できませんでした")
return None
except sr.RequestError as e:
print(f"[!] 音声認識サービスエラー: {e}")
return None
def ask_ollama(user_message):
"""Ollamaに問い合わせて応答を取得する"""
conversation_history.append({"role": "user", "content": user_message})
print("[*] AIが考えています...")
response = ollama.chat(
model=OLLAMA_MODEL,
messages=conversation_history,
)
assistant_message = response["message"]["content"]
conversation_history.append({"role": "assistant", "content": assistant_message})
# 履歴が長くなりすぎたら古いものを削除(system promptは残す)
if len(conversation_history) > 21:
conversation_history[1:3] = []
return assistant_message
def speak_voicevox(text):
"""VOICEVOXで音声合成して再生する"""
# 1. 音声合成用のクエリを作成
query_resp = requests.post(
f"{VOICEVOX_HOST}/audio_query",
params={"text": text, "speaker": SPEAKER_ID},
timeout=30,
)
query_resp.raise_for_status()
query_data = query_resp.json()
# 速度とピッチの調整(お好みで)
query_data["speedScale"] = 1.2
query_data["pitchScale"] = 0.0
# 2. 音声合成を実行
synth_resp = requests.post(
f"{VOICEVOX_HOST}/synthesis",
params={"speaker": SPEAKER_ID},
headers={"Content-Type": "application/json"},
data=json.dumps(query_data),
timeout=60,
)
synth_resp.raise_for_status()
# 3. WAVデータを再生
play_wav(synth_resp.content)
def play_wav(wav_data):
"""WAVバイナリデータを再生する"""
try:
import pyaudio
with io.BytesIO(wav_data) as wav_io:
with wave.open(wav_io, 'rb') as wf:
p = pyaudio.PyAudio()
stream = p.open(
format=p.get_format_from_width(wf.getsampwidth()),
channels=wf.getnchannels(),
rate=wf.getframerate(),
output=True,
)
chunk_size = 1024
data = wf.readframes(chunk_size)
while data:
stream.write(data)
data = wf.readframes(chunk_size)
stream.stop_stream()
stream.close()
p.terminate()
except Exception as e:
# PyAudioで再生できない場合、ファイルに保存して再生
import tempfile
import subprocess
with tempfile.NamedTemporaryFile(suffix=".wav", delete=False) as f:
f.write(wav_data)
tmp_path = f.name
# Windows
subprocess.run(["powershell", "-c", f'(New-Object Media.SoundPlayer "{tmp_path}").PlaySync()'])
def main():
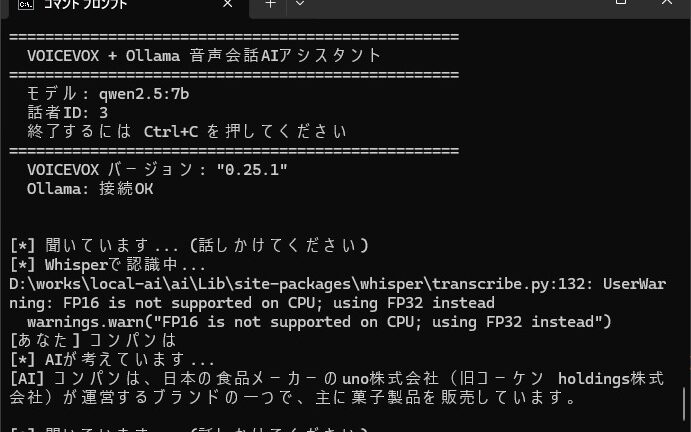
print("=" * 50)
print(" VOICEVOX + Ollama 音声会話AIアシスタント")
print("=" * 50)
print(f" モデル: {OLLAMA_MODEL}")
print(f" 話者ID: {SPEAKER_ID}")
print(" 終了するには Ctrl+C を押してください")
print("=" * 50)
# VOICEVOXの接続確認
try:
resp = requests.get(f"{VOICEVOX_HOST}/version", timeout=5)
print(f" VOICEVOX バージョン: {resp.text}")
except requests.ConnectionError:
print("[!] VOICEVOXに接続できません。起動しているか確認してください。")
return
# Ollamaの接続確認
try:
ollama.list()
print(" Ollama: 接続OK")
except Exception:
print("[!] Ollamaに接続できません。起動しているか確認してください。")
return
print()
while True:
try:
# 1. 音声入力
user_text = listen_from_mic()
if user_text is None:
continue
# 終了ワード
if user_text in ("終了", "おわり", "ストップ", "バイバイ"):
print("[AI] さようなら!")
speak_voicevox("さようなら!またお話ししましょう!")
break
# 2. LLMで応答生成
response_text = ask_ollama(user_text)
print(f"[AI] {response_text}")
# 3. 音声合成で読み上げ
speak_voicevox(response_text)
except KeyboardInterrupt:
print("\n[*] 終了します")
break
if __name__ == "__main__":
main()使い方
1. VOICEVOXを起動する
VOICEVOXアプリを起動し、エンジンが立ち上がるのを待つ。タスクトレイにアイコンが表示されていればOKだ。
2. Ollamaを起動する
Ollamaがバックグラウンドで動いていることを確認する。通常はインストール後に自動起動しているはずだが、動いていなければ以下で起動する。
ollama serve3. スクリプトを実行する
python voice_assistant.py「聞いています…」と表示されたらマイクに話しかけるだけ。AIが応答を考えてVOICEVOXが読み上げてくれる。
カスタマイズ
話者を変更する
スクリプト冒頭の SPEAKER_ID を変更するだけで話者を切り替えられる。先述の話者一覧から好きなキャラのIDを指定しよう。
SPEAKER_ID = 8 # 春日部つむぎに変更AIの性格を変更する
SYSTEM_PROMPT を変更すれば、AIの応答スタイルを自由にカスタマイズできる。
# ツンデレ風
SYSTEM_PROMPT = "あなたはツンデレなAIアシスタントです。素直になれないけど実は親切。日本語で短く答えてください。"
# 博士キャラ風
SYSTEM_PROMPT = "あなたは天才科学者のAIアシスタントです。語尾に「なのだ」をつけて話してください。"
# 関西弁
SYSTEM_PROMPT = "あなたは大阪出身のAIアシスタントです。関西弁で陽気に答えてください。"読み上げ速度を調整する
speak_voicevox 関数内の speedScale と pitchScale で読み上げの速さと声の高さを変えられる。
| パラメータ | デフォルト | 説明 |
|---|---|---|
| speedScale | 1.0 | 読み上げ速度(1.2で少し速め、0.8で遅め) |
| pitchScale | 0.0 | 声の高さ(正で高く、負で低く) |
| volumeScale | 1.0 | 音量 |
| intonationScale | 1.0 | 抑揚の強さ |
音声認識をWhisperに変更する(完全オフライン化)
デフォルトではGoogleの音声認識APIを使っているため、音声認識の部分だけインターネット接続が必要になる。完全にオフラインで動かしたい場合は、OpenAIのWhisperを使おう。
pip install openai-whisperlisten_from_mic 関数を以下のように書き換える。
import whisper
import numpy as np
import tempfile
# Whisperモデルを読み込み(初回はダウンロードが走る)
whisper_model = whisper.load_model("base") # tiny, base, small, medium, large
def listen_from_mic():
"""マイクから音声を取得してWhisperで認識する"""
recognizer = sr.Recognizer()
with sr.Microphone(sample_rate=16000) as source:
print("\n[*] 聞いています... (話しかけてください)")
recognizer.adjust_for_ambient_noise(source, duration=0.5)
try:
audio = recognizer.listen(source, timeout=10, phrase_time_limit=30)
print("[*] Whisperで認識中...")
# AudioDataをNumPy配列に変換
wav_data = audio.get_wav_data()
with io.BytesIO(wav_data) as wav_io:
with wave.open(wav_io, 'rb') as wf:
frames = wf.readframes(wf.getnframes())
audio_np = np.frombuffer(frames, dtype=np.int16).astype(np.float32) / 32768.0
result = whisper_model.transcribe(audio_np, language="ja")
text = result["text"].strip()
if text:
print(f"[あなた] {text}")
return text
return None
except sr.WaitTimeoutError:
print("[!] タイムアウト: 音声が検出されませんでした")
return NoneWhisperのモデルサイズと精度は以下の通り。
| モデル | サイズ | 日本語精度 | 速度 |
|---|---|---|---|
| tiny | 約75MB | 低い | 最速 |
| base | 約150MB | そこそこ | 速い |
| small | 約500MB | 良好 | 普通 |
| medium | 約1.5GB | 高い | 遅め |
| large | 約3GB | 最高 | 遅い |
GPUがあれば small 以上をおすすめする。CPUのみなら base が現実的なラインだろう。
トラブルシューティング
| 症状 | 原因 | 対策 |
|---|---|---|
| VOICEVOXに接続できない | エンジン未起動 | VOICEVOXアプリを起動する。ポート50021が使われていないか確認 |
| 音声が認識されない | マイクの設定ミス | OSの入力デバイス設定を確認。SpeechRecognitionは既定のマイクを使う |
| PyAudioのインストールエラー | ビルドツール不足 | 前述のpipwinまたはwhlファイルで対処 |
| Ollamaの応答が遅い | モデルが大きすぎる | 軽量モデル(3b前後)に切り替える。またはGPUを活用 |
| 日本語の認識精度が低い | Google API側の問題 or 環境音 | Whisperに切り替える。静かな環境で使う |
| 音声が途切れる | 長文の応答 | SYSTEM_PROMPTに「短く答えて」を追加する |
さらに発展させるには
基本の仕組みが動いたら、以下のような拡張も面白い。
- Wake Word対応: 「ねえ、ずんだもん」のようなキーワードで起動するようにする(pvporcupineなどを使用)
- GUIを追加: tkinterやStreamlitで簡易UIを作り、会話ログの表示や設定変更をできるようにする
- RAG連携: ローカルのドキュメントを読み込ませて、自分専用の知識を持ったアシスタントにする
- 感情分析: ユーザーの発言の感情を分析して、VOICEVOXの話者スタイル(嬉しい/悲しい等)を動的に切り替える
- ストリーミング応答: Ollamaのストリーミングレスポンスを使い、文単位で逐次読み上げることで体感速度を上げる
まとめ
VOICEVOX + Ollama の組み合わせで、ローカルで完結する音声会話AIアシスタントが意外と簡単に作れる。外部サービスに依存しないためプライバシー面でも安心だし、好きなキャラの声で会話できるのは純粋に楽しい。
Pythonスクリプト1本で音声認識・LLM推論・音声合成を繋げているだけなので、カスタマイズの余地も大きい。システムプロンプトや話者を変えるだけで、全く違うキャラクターのアシスタントが生まれる。ぜひ自分好みに仕上げてみてほしい。







Add comment